
volatile 关键字
参考文献:面试官最爱的volatile关键字
1. volatile 关键字的作用
- 保证了不同线程对该变量操作的内存可见性
- 禁止指令重排序
2. java 内存模型
Java 虚拟机规范试图定义一种 Java 内存模型(JMM), 来屏蔽掉各种硬件和操作系统的内存访问差异,让 Java 程序在各种平台上都能达到一致的内存访问效果。简单来说,由于 CPU 执行指令的速度是很快的,但是内存访问的速度就慢了很多,相差的不是一个数量级,所以搞处理器的那群大佬们又在 CPU 里加了好几层高速缓存。
在 Java 内存模型里,对上述的优化又进行了一波抽象。JMM 规定所有变量都是存在主存中的,类似于上面提到的普通内存,每个线程又包含自己的工作内存,方便理解就可以看成 CPU 上的寄存器或者高速缓存。所以线程的操作都是以工作内存为主,它们只能访问自己的工作内存,且工作前后都要把值在同步回主内存。
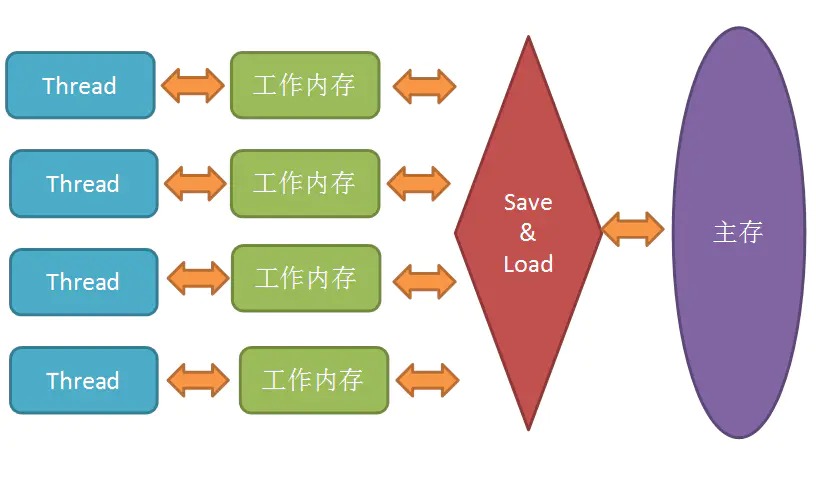
在线程执行时,首先会从主存中 read 变量值,再 load 到工作内存中的副本中,然后再传给处理器执行,执行完毕后再给工作内存中的副本赋值,随后工作内存再把值传回给主存,主存中的值才更新。
使用工作内存和主存,虽然加快的速度,但是也带来了一些问题。比如看下面一个例子:
i = i + 1;
假设i初值为 0,当只有一个线程执行它时,结果肯定得到 1,当两个线程执行时,会得到结果 2 吗?这倒不一定了。可能存在这种情况:
线程1: load i from 主存 // i = 0
i + 1 // i = 1
线程2: load i from主存 // 因为线程1还没将i的值写回主存,所以i还是0
i + 1 //i = 1
线程1: save i to 主存
线程2: save i to 主存
如果两个线程按照上面的执行流程,那么i最后的值居然是 1 了。如果最后的写回生效的慢,你再读取 i 的值,都可能是 0,这就是缓存不一致问题。
JMM 主要就是围绕着如何在并发过程中如何处理原子性、可见性和有序性这 3 个特征来建立的,通过解决这三个问题,可以解除缓存不一致的问题。而 volatile 跟可见性和有序性都有关。
3. 三大特性
3.1 原子性
Java中,对基本数据类型的读取和赋值操作是原子性操作,所谓原子性操作就是指这些操作是不可中断的,要做一定做完,要么就没有执行。 比如:
i = 2;
j = i;
i++;
i = i + 1;
上面 4 个操作中,i=2 是读取操作,必定是原子性操作,j=i 你以为是原子性操作,其实吧,分为两步,一是读取 i 的值,然后再赋值给 j,这就是 2 步操作了,称不上原子操作,i++ 和 i = i + 1 其实是等效的,读取 i 的值,加 1,再写回主存,那就是 3 步操作了。所以上面的举例中,最后的值可能出现多种情况,就是因为满足不了原子性。
这么说来,只有简单的读取,赋值是原子操作,还只能是用数字赋值,用变量的话还多了一步读取变量值的操作。有个例外是,虚拟机规范中允许对 64 位数据类型 ( long 和 double ),分为 2 次 32 为的操作来处理,但是最新 JDK 实现还是实现了原子操作的。
JMM 只实现了基本的原子性,像上面 i++ 那样的操作,必须借助于 synchronized 和 Lock 来保证整块代码的原子性了。线程在释放锁之前,必然会把 i 的值刷回到主存的。
3.2 可见性
说到可见性,Java 就是利用 volatile 来提供可见性的。 当一个变量被 volatile 修饰时,那么对它的修改会立刻刷新到主存,当其它线程需要读取该变量时,会去内存中读取新值。而普通变量则不能保证这一点。
其实通过 synchronized 和 Lock 也能够保证可见性,线程在释放锁之前,会把共享变量值都刷回主存,但是 synchronized 和 Lock 的开销都更大。
3.3 有序性
JMM 是允许编译器和处理器对指令重排序的,但是规定了 as-if-serial 语义,即不管怎么重排序,程序的执行结果不能改变。比如下面的程序段:
double pi = 3.14; //A
double r = 1; //B
double s= pi * r * r;//C
上面的语句,可以按照 A->B->C 执行,结果为 3.14,但是也可以按照 B->A->C 的顺序执行,因为 A、B 是两句独立的语句,而 C 则依赖于 A、B,所以 A、B 可以重排序,但是 C 却不能排到 A、B 的前面。JMM 保证了重排序不会影响到单线程的执行,但是在多线程中却容易出问题。
比如这样的代码:
int a = 0;
bool flag = false;
public void write() {
a = 2; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}
假如有两个线程执行上述代码段,线程 1 先执行 write,随后线程 2 再执行 multiply,最后 ret 的值一定是 4 吗?结果不一定:
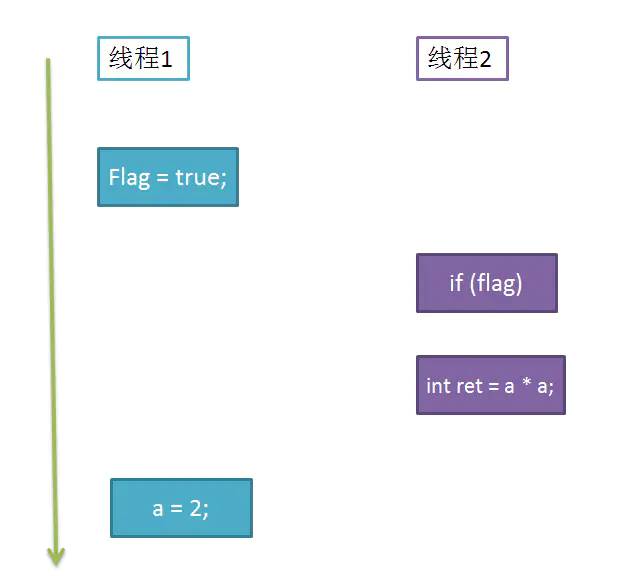
如图所示,write 方法里的 1 和 2 做了重排序,线程 1 先对 flag 赋值为 true,随后执行到线程 2,ret 直接计算出结果,再到线程 1,这时候 a 才赋值为 2,很明显迟了一步。
这时候可以为 flag 加上 volatile 关键字,禁止重排序,可以确保程序的“有序性”,也可以上重量级的 synchronized 和 Lock 来保证有序性,它们能保证那一块区域里的代码都是一次性执行完毕的。
另外,JMM 具备一些先天的有序性,即不需要通过任何手段就可以保证的有序性,通常称为 happens-before 原则。<<JSR-133:Java Memory Model and Thread Specification>>定义了如下 happens-before 规则:
程序顺序规则: 一个线程中的每个操作,happens-before 于该线程中的任意后续操作
监视器锁规则:对一个线程的解锁,happens-before 于随后对这个线程的加锁
volatile变量规则: 对一个 volatile 域的写,happens-before 于后续对这个 volatile 域的读
传递性:如果A happens-before B ,且 B happens-before C, 那么 A happens-before C
start()规则: 如果线程 A 执行操作
ThreadB_start()(启动线程B) , 那么 A 线程的ThreadB_start()happens-before 于 B 中的任意操作join()原则: 如果 A 执行
ThreadB.join()并且成功返回,那么线程 B 中的任意操作 happens-before 于线程 A 从ThreadB.join()操作成功返回。interrupt()原则: 对线程
interrupt()方法的调用先行发生于被中断线程代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测是否有中断发生finalize()原则:一个对象的初始化完成先行发生于它的
finalize()方法的开始
第 1 条规则程序顺序规则是说在一个线程里,所有的操作都是按顺序的,但是在 JMM 里其实只要执行结果一样,是允许重排序的,这边的 happens-before 强调的重点也是单线程执行结果的正确性,但是无法保证多线程也是如此。
第 2 条规则监视器规则其实也好理解,就是在加锁之前,确定这个锁之前已经被释放了,才能继续加锁。
第 3 条规则,就适用到所讨论的 volatile,如果一个线程先去写一个变量,另外一个线程再去读,那么写入操作一定在读操作之前。
第 4 条规则,就是 happens-before 的传递性。
后面几条就不再一一赘述了。
4. volatile关键字如何满足并发编程的三大特性的?
那就要重提 volatile 变量规则: 对一个 volatile 域的写,happens-before 于后续对这个 volatile 域的读。 这条再拎出来说,其实就是如果一个变量声明成是 volatile 的,那么当我读变量时,总是能读到它的最新值,这里最新值是指不管其它哪个线程对该变量做了写操作,都会立刻被更新到主存里,我也能从主存里读到这个刚写入的值。也就是说 volatile 关键字可以保证可见性以及有序性。
继续拿上面的一段代码举例:
int a = 0;
bool flag = false;
public void write() {
a = 2; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}
这段代码不仅仅受到重排序的困扰,即使 1、2 没有重排序。3 也不会那么顺利的执行的。假设还是线程 1 先执行 write 操作,线程 2 再执行 multiply 操作,由于线程 1 是在工作内存里把 flag 赋值为 1,不一定立刻写回主存,所以线程 2 执行时,multiply 再从主存读 flag 值,仍然可能为 false,那么括号里的语句将不会执行。
如果改成下面这样:
int a = 0;
volatile bool flag = false;
public void write() {
a = 2; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}
那么线程 1 先执行 write,线程 2 再执行 multiply。根据 happens-before 原则,这个过程会满足以下 3 类规则:
- 程序顺序规则:1 happens-before 2; 3 happens-before 4; (volatile限制了指令重排序,所以1 在2 之前执行)
- volatile规则:2 happens-before 3
- 传递性规则:1 happens-before 4
从内存语义上来看
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效,线程接下来将从主内存中读取共享变量。
5. volatile的能保证可见性和有序性,但是能保证原子性吗?
首先我回答是不能保证原子性,要是说能保证,也只是对单个 volatile 变量的读/写具有原子性,但是对于类似 volatile++ 这样的复合操作就无能为力了,比如下面的例子:
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}
按道理来说结果是 10000,但是运行下很可能是个小于 10000 的值。有人可能会说 volatile 不是保证了可见性啊,一个线程对 inc 的修改,另外一个线程应该立刻看到啊!可是这里的操作 inc++ 是个复合操作啊,包括读取 inc 的值,对其自增,然后再写回主存。
假设线程 A,读取了 inc 的值为 10,这时候被阻塞了,因为没有对变量进行修改,触发不了 volatile 规则。
线程 B 此时也读读 inc 的值,主存里 inc 的值依旧为 10,做自增,然后立刻就被写回主存了,为 11。
此时又轮到线程 A 执行,由于工作内存里保存的是 10,所以继续做自增,再写回主存,11 又被写了一遍。所以虽然两个线程执行了两次 increase(),结果却只加了一次。
有人说,volatile不是会使缓存行无效的吗?但是这里线程 A 读取到线程 B 也进行操作之前,并没有修改 inc 值,所以线程 B 读取的时候,还是读的 10。
又有人说,线程 B 将 11 写回主存,不会把线程 A 的缓存行设为无效吗?但是线程 A 的读取操作已经做过了啊,只有在做读取操作时,发现自己缓存行无效,才会去读主存的值,所以这里线程 A 只能继续做自增了。
综上所述,在这种复合操作的情景下,原子性的功能是维持不了了。但是 volatile 在上面那种设置 flag 值的例子里,由于对 flag 的读/写操作都是单步的,所以还是能保证原子性的。
要想保证原子性,只能借助于 synchronized,Lock 以及并发包下的 atomic 的原子操作类了,即对基本数据类型的 自增(加1操作),自减(减1操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。
6. volatile 底层实现机制
如果把加入 volatile 关键字的代码和未加上 volatile 关键字的代码都生成汇编代码,会发现加入 volatile 关键字的代码会多出一个 lock 前缀指令。
lock 前缀指令实际相当于一个内存屏障,内存屏障提供了以下功能:
1 . 重排序时不能把后面的指令重排序到内存屏障之前的位置
2 . 使得本 CPU 的 Cache 写入内存
3 . 写入动作也会引起别的 CPU 或者别的内核无效化其 Cache,相当于让新写入的值对别的线程可见。
7. 哪里会使用到 volatile
7.1 场景一
场景描述:一个变量被多个线程共享,线程直接给这个变量赋值。 可以保证变量的线程安全
状态量标记,就如上面对 flag 的标记:
int a = 0;
volatile bool flag = false;
public void write() {
a = 2; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}
这种对变量的读写操作,标记为 volatile 可以保证修改对线程立刻可见。比 synchronized,Lock 有一定的效率提升。
注意!!!
volatile 不适用于非原子操作,例如 i++
总的来说,必须同时满足下面两个条件才能保证在并发环境的线程安全:
- 对变量的写操作不依赖于当前值(比如 i++),或者说是单纯的变量赋值(boolean flag = true)。
- 该变量没有包含在具有其他变量的不变式中,也就是说,不同的 volatile 变量之间,不能互相依赖。只有在状态真正独立于程序内其他内容时才能使用 volatile。
7.2 场景二
场景描述:禁止重排序
例子
单例模式的实现,典型的双重检查锁定(DCL)
class Singleton{
private volatile static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}
这是一种懒汉的单例模式,使用时才创建对象,而且为了避免初始化操作的指令重排序,给 instance 加上了 volatile。
那 DCL 为什么要加 volatile 关键字呢?
了解下 singleton = new Singleton() 这段代码其实不是原子性的操作,它至少分为以下3个步骤:
- 给 singleton 对象分配内存空间
- 调用 Singleton 类的构造函数等,初始化 singleton 对象
- 将 singleton 对象指向分配的内存空间,这步一旦执行了,那 singleton 对象就不等于 null 了
这里还需要知道一点,就是有时候 JVM 会为了优化,而做指令重排序的操作,这里的指令,指的是 CPU 层面的。
正常情况下,singleton = new Singleton() 的步骤是按照 1->2->3 这种步骤进行的,但是一旦 JVM 做了指令重排序,那么顺序很可能编程 1->3->2,如果是这种顺序,可以发现,在 3 步骤执行完 singleton 对象就不等于 null,但是它其实还没做步骤二的初始化工作,但是另一个线程进来时发现,singleton不等于null了,就这样把半成品的实例返回去,调用是会报错的。