
参考文档:
redis 的过期策略都有哪些?内存淘汰机制都有哪些?
Redis的数据过期清除策略 与 内存淘汰策略
Redis的LFU算法源码实现解析
1. 过期策略
Redis 是 key-value 数据库,我们可以设置 Redis 中缓存的 key 的过期时间。Redis 的过期策略就是指当 Redis 中缓存的 key 过期了,Redis 如何处理。
过期策略通常有以下三种:
- 定时过期:每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的 CPU 资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
- 惰性过期:只有当访问一个 key 时,才会判断该 key 是否已过期,过期则清除。该策略可以最大化地节省 CPU 资源,却对内存非常不友好。极端情况可能出现大量的过期 key 没有再次被访问,从而不会被清除,占用大量内存。
- 定期过期:每隔一定的时间,会扫描一定数量的数据库的 expires 字典中一定数量的 key,并清除其中已过期的 key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得 CPU 和内存资源达到最优的平衡效果。(expires 字典会保存所有设置了过期时间的 key 的过期时间数据,其中,key 是指向键空间中的某个键的指针,value 是该键的毫秒精度的 UNIX 时间戳表示的过期时间。键空间是指该 Redis 集群中保存的所有键。)
Redis 中同时使用了惰性过期和定期过期两种过期策略。
2. 内存淘汰策略
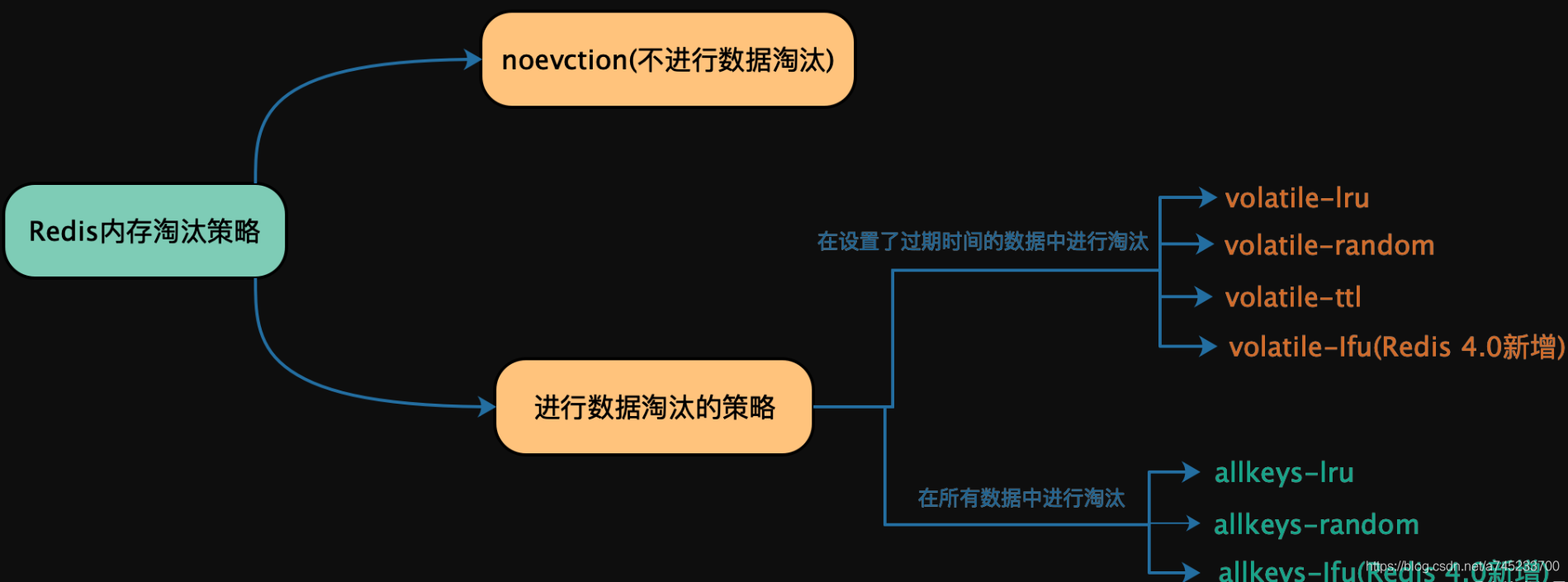
Redis 的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key。
- allkeys-lfu:在所有的键值对中,移除最近最不频繁使用的键值对,4.0 新增。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除。
- volatile-lfu:在设置了过期时间的键值对中,移除最近最不频繁使用的键值对,4.0 新增。
通常情况下推荐优先使用 allkeys-lru 策略。这样可以充分利用 LRU 这一经典缓存算法的优势,把最近最常访问的数据留在缓存中,提升应用的访问性能。
如果你的业务数据中有明显的冷热数据区分,建议使用 allkeys-lru 策略。
如果业务应用中的数据访问频率相差不大,没有明显的冷热数据区分,建议使用 allkeys-random 策略,随机选择淘汰的数据就行。
如果没有设置过期时间的键值对,那么 volatile-lru,volatile-lfu,volatile-random 和 volatile-ttl 策略的行为, 和 noeviction 基本上一致。
3. LRU 实现
LRU(Least Recently Uses) 是一个缓存置换算法,在缓存有限的情况下,如果有新的数据加载至缓存,则需要考虑将不会再继续被访问的数据剔除掉,但是缓存是否会被访问是没有办法预测的,所以,LRU 是基于一个假设实现:
很久未使用的 key 不会被再次使用。
这也是 LRU 实现的一个思路,它首先实现一个双向链表,当一个 key 被访问时,则将这个 key 放到双向链表的头部,当时缓存不可用时,从尾部逐个剔除。
我们看一个实现
import java.util.HashMap;
import java.util.Map;
public class Solution {
private int capacity;
private Map<Integer, Node> map;
private Node head;
private Node tail;
class Node {
int key;
int value;
Node prev;
Node nextV;
public Node(int key, int value, Node prev, Node nextV) {
this.key = key;
this.value = value;
this.prev = prev;
this.nextV = nextV;
}
}
public Solution(int capacity) {
this.capacity = capacity;
map = new HashMap<>();
}
public int get(int key) {
if (!map.containsKey(key)) return -1;
makeRecently(key);
return map.get(key).value;
}
public void set(int key, int value) {
// 如果 key 已存在,直接修改值,再移到链表头部
if (map.containsKey(key)) {
map.get(key).value = value;
makeRecently(key);
return;
}
if (map.size() == capacity) {
// 移除时 tail 一定存在
map.remove(tail.key);
tail = tail.prev;
tail.nextV = null;
}
head = new Node(key, value, null, head);
map.put(key, head);
if (map.size() == 1) {
tail = head;
} else {
head.nextV.prev = head;
}
}
/**
* 使 key 所在节点,置于双向列表最前端
*
* @param key
*/
private void makeRecently(int key) {
Node node = map.get(key);
if (node != head) {
node.prev.nextV = node.nextV;
if (node != tail) {
node.nextV.prev = node.prev;
} else {
tail = node.prev;
}
node.prev = null;
node.nextV = head;
head.prev = node;
head = node;
}
}
public static void main(String[] args) {
Solution s = new Solution(2);
s.set(1, 1); //将(1,1)插入缓存,缓存是{"1"=1},set操作返回"null"
s.set(2, 2); //将(2,2)插入缓存,缓存是{"2"=2,"1"=1},set操作返回"null"
s.get(1);// 因为get(1)操作,缓存更新,缓存是{"1"=1,"2"=2},get操作返回"1"
s.set(3, 3); //将(3,3)插入缓存,缓存容量是2,故去掉某尾的key-value,缓存是{"3"=3,"1"=1},set操作返回"null"
s.get(2);// 因为get(2)操作,不存在对应的key,故get操作返回"-1"
s.set(4, 4); //将(4,4)插入缓存,缓存容量是2,故去掉某尾的key-value,缓存是{"4"=4,"3"=3},set操作返回"null"
s.get(1);// 因为get(1)操作,不存在对应的key,故get操作返回"-1"
s.get(3);//因为get(3)操作,缓存更新,缓存是{"3"=3,"4"=4},get操作返回"3"
s.get(4);//因为get(4)操作,缓存更新,缓存是{"4"=4,"3"=3},get操作返回"4"
}
}
LRU 算法在实际实现时,需要用链表管理所有的缓存数据,移除元素时直接从链表队尾移除,增加时加到头部就可以了,但这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
假设我们现在有一张数据表,执行如下 SQL 语句:
SELECT * FROM table_name;
上面这条 SQL 的作用是将数据表中的所有数据读取出来,我们再将该数据表中的所有数据读取出后就不再继续使用,那么对于 LRU 的双向链表在头部会有大量数据占用,导致热点数据被逐出缓存以致于会出现大量磁盘 I/O。
MySQL Innodb 的 buufer pool 实现了一个改进版的 LRU,它将 LRU 的双向链表分为两部分,一个是 newlist 另一个是 oldlist,newlist 主要是用于存放头部热点数据,oldlist 用于存放非热点数据,当首次加载一个 page 时,会将数据放到 oldlist 的头部,再次访问的时候会移动到 newlist。
在 Redis 中,LRU 算法被做了简化,以减轻数据淘汰对缓存性能的影响。
具体来说:
- Redis 默认会记录每个数据的最近一次访问的时间戳(由键值对数据结构 RedisObject 中的 lru 字段记录)。
- Redis 中会维护一个 Pool,Pool 中最大可以容纳 16 个 Key,按照 key 的空闲时间进行排序,空闲时间就是当前时间和上一次访问时间戳之间的差值,空闲时间越大说明 key 越长时间没有被访问,应该被淘汰。
- 当每次要淘汰 key 的时候,会随机抽取若干个 key,计算其空闲时间,如果 Pool 还没有满或者空闲时间比 Pool 中的 最小空闲时间 大的话,就将空闲时间小的 Key 从 Pool 中移除,将 Key 加入到 Pool 中。
- 当要淘汰 key 的时候,将 Pool 中的空闲时间最大的 key 对应的数据移除内存。
这样一来,Redis 缓存不用为所有的数据维护一个大链表,也不用在每次数据访问时都移动链表项,提升了缓存的性能。
RedisObject 的定义如下:(简单理解为一个 key-value)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
4. LFU 算法
LFU 是在 Redis4.0 后出现的,它的核心思想是根据 key 的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。LFU 算法能更好的表示一个 key 被访问的热度。假如你使用的是 LRU 算法,一个 key 很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些 key 将来是很有可能被访问到的则被淘汰了。如果使用 LFU 算法则不会出现这种情况,因为使用一次并不会使一个 key 成为热点数据。它的使用与 LRU 有所区别:
- LFU (Least Frequently Used) :最近最不频繁使用,跟使用的次数有关,淘汰使用次数最少的。
- LRU (Least Recently Used):最近最少使用,跟使用的最后一次时间有关,淘汰最近使用时间离现在最久的。
LFU 实现比较复杂,需要考虑几个问题:
- 如果实现为链表,当对象被访问时按访问次数移动到链表的某个有序位置可能是低效的,因为可能存在大量访问次数相同的 key,最差情况是O(n)
- 某些 key 访问次数可能非常之大,理论上可以无限大,但实际上我们并不需要精确的访问次数
- 访问次数特别大的 key 可能以后都不再访问了,但是因为访问次数大而一直占用着内存不被淘汰,需要一个方法来逐步“驱除”(有点 LRU的意思),最简单的就是逐步衰减访问次数
通过 LRU 算法的学习,现在我们已经了解到,每个键值对的值都对应了一个 redisObject 结构体,其中有一个 24 bits 的 lru 变量。lru 变量在 LRU 算法实现时,是用来记录数据的访问时间戳。因为 Redis server 每次运行时,只能将 maxmemory-policy 配置项设置为使用一种淘汰策略,所以,LRU 算法和 LFU 算法并不会同时使用。而为了节省内存开销,Redis 源码就复用了 lru 变量来记录 LFU 算法所需的访问频率信息。
Redis 只用了 24bit (server.lruclock 也是24bit)来记录上述的信息,是的不是 24byte,连32位指针都放不下!
- 16bit : 上一次递减时间 (解决第三个问题)
- 8bit : 访问次数 (解决第二个问题)
4.1 键值对访问频率的初始化与更新
对于键值对访问频率的初始化来说,当一个键值对被创建后,createObject 函数就会被调用,用来分配 redisObject 结构体的空间和设置初始化值。如果 Redis 将 maxmemory-policy 设置为 LFU 算法,那么,键值对 redisObject 结构体中的 lru 变量初始化值,会由两部分组成:
- 第一部分是 lru 变量的高 16 位,是以 1 分钟为精度的 UNIX 时间戳。这是通过调用 LFUGetTimeInMinutes 函数(在 evict.c 文件中)计算得到的。
- 第二部分是 lru 变量的低 8 位,被设置为宏定义 LFU_INIT_VAL(在server.h文件中),默认值为 5。
当一个键值对被访问时,Redis 会调用 lookupKey 函数进行查找。当 maxmemory-policy 设置使用 LFU 算法时,lookupKey 函数会调用 updateLFU 函数来更新键值对的访问频率,也就是 lru 变量值。
- 根据距离上次访问的时长,衰减访问次数。
- 根据当前访问更新访问次数。
- 更新 lru 变量值
思考一个问题:访问键值对时不是要增加键值对的访问次数吗,为什么要先衰减访问次数呢?
其实,这就是我在前面一开始和你介绍的,LFU 算法是根据访问频率来淘汰数据的,而不只是访问次数。访问频率需要考虑键值对的访问是多长时间段内发生的。键值对的先前访问距离当前时间越长,那么这个键值对的访问频率相应地也就会降低。
我给你举个例子,假设数据 A 在时刻 T 到 T+10 分钟这段时间内,被访问了 30 次,那么,这段时间内数据 A 的访问频率可以计算为 3 次 / 分钟(30 次 /10 分钟 = 3 次 / 分钟)。
紧接着,在 T+10 分钟到 T+20 分钟这段时间内,数据 A 没有再被访问,那么此时,如果我们计算数据 A 在 T 到 T+20 分钟这段时间内的访问频率,它的访问频率就会降为 1.5 次 / 分钟(30 次 /20 分钟 = 1.5 次 / 分钟)。以此类推,随着时间的推移,如果数据 A 在 T+10 分钟后一直没有新的访问,那么它的访问频率就会逐步降低。这就是所谓的访问频率衰减。
因为 Redis 是使用 lru 变量中的访问次数来表示访问频率,所以在每次更新键值对的访问频率时,就会通过 LFUDecrAndReturn 函数对访问次数进行衰减。
具体来说,LFUDecrAndReturn 函数会首先获取当前键值对的上一次访问时间,这是保存在 lru 变量高 16 位上的值。然后,LFUDecrAndReturn 函数会根据全局变量 server 的 lru_decay_time 成员变量的取值,来计算衰减的大小 num_period。
这个计算过程会判断 lfu_decay_time(衰减时间) 的值是否为 0。如果 lfu_decay_time 值为 0,那么衰减大小也为 0。此时,访问次数不进行衰减。
否则的话,LFUDecrAndReturn 函数会调用 LFUTimeElapsed 函数,计算距离键值对的上一次访问已经过去的时长。这个时长也是以 1 分钟为精度来计算的。有了距离上次访问的时长后,LFUDecrAndReturn 函数会把这个时长除以 lfu_decay_time 的值,并把结果作为访问次数的衰减大小。
这里,你需要注意的是,lfu_decay_time 变量值,是由 redis.conf 文件中的配置项 lfu-decay-time 来决定的。
Redis 在初始化时,会通过 initServerConfig 函数来设置 lfu_decay_time 变量的值,默认值为 1。所以,在默认情况下,访问次数的衰减大小就是等于上一次访问距离当前的分钟数。比如,假设上一次访问是 10 分钟前,那么在默认情况下,访问次数的衰减大小就等于 10。
当然,如果上一次访问距离当前的分钟数,已经超过访问次数的值了,那么访问次数就会被设置为 0,这就表示键值对已经很长时间没有被访问了。
然后我们看下根据当前访问更新访问次数的源码
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
// 对数递增计数值
//核心就是访问次数越大,访问次数被递增的可能性越小,最大 255,此外你可以在配置 redis.conf 中写明访问多少次递增多少。
uint8_t LFULogIncr(uint8_t counter) {
// 到最大值了,不能在增加了
if (counter == 255) return 255;
// rand()产生一个0-0x7fff的随机数,一个随机数去除以 RAND_MAX也就是Ox7FFF,也就是随机概率
double r = (double)rand()/RAND_MAX;
// 减去新对象初始化的基数值 (LFU_INIT_VAL 默认是 5)
double baseval = counter - LFU_INIT_VAL;
// baseval 如果小于零,说明这个对象快不行了,不过本次 incr 将会延长它的寿命
if (baseval < 0) baseval = 0;
// baseval * LFU 对数计数器因子 + 1保证分母大于1
// 当 baseval 特别大时,最大是 (255-5),p 值会非常小,很难会走到 counter++ 这一步
// p 就是 counter 通往 [+1] 权力的门缝,baseval 越大,这个门缝越窄,通过就越艰难
double p = 1.0/(baseval*server.lfu_log_factor+1);
// 如果随机概率小于当前计算的访问概率,那么访问次数加1
if (r < p) counter++;
return counter;
}
- 第一个分支对应了当前访问次数等于最大值 255 的情况。此时,LFULogIncr 函数不再增加访问次数。
- 第二个分支对应了当前访问次数小于 255 的情况。此时,LFULogIncr 函数会计算一个阈值 p,以及一个取值为 0 到 1 之间的随机概率值 r。如果概率 r 小于阈值 p,那么 LFULogIncr 函数才会将访问次数加 1。否则的话,LFULogIncr 函数会返回当前的访问次数,不做更新。
从这里你可以看到,因为概率值 r 是随机定的,所以,阈值 p 的大小就决定了访问次数增加的难度。阈值 p 越小,概率值 r 小于 p 的可能性也越小,此时,访问次数也越难增加;相反,如果阈值 p 越大,概率值 r 小于 p 的可能性就越大,访问次数就越容易增加。
而阈值 p 的值大小,其实是由两个因素决定的。一个是当前访问次数和宏定义 LFU_INIT_VAL 的差值 baseval,另一个是 reids.conf 文件中定义的配置项 lfu-log-factor。
当计算阈值 p 时,我们是把 baseval 和 lfu-log-factor 乘积后,加上 1,然后再取其倒数。所以,baseval 或者 lfu-log-factor 越大,那么其倒数就越小,也就是阈值 p 就越小;反之,阈值 p 就越大。也就是说,这里其实就对应了两种影响因素。
baseval 的大小:这反映了当前访问次数的多少。比如,访问次数越多的键值对,它的访问次数再增加的难度就会越大;
lfu-log-factor 的大小:这是可以被设置的。也就是说,Redis 源码提供了让我们人为调节访问次数增加难度的方法。
这样,等到 LFULogIncr 函数执行完成后,键值对的访问次数就算更新完了。
4.2 小结
- LFU 是在 Redis 4.0 新增的淘汰策略,它涉及的巧妙之处在于,其复用了 redisObject 结构的 lru 字段,把这个字段一分为二,高 16 位保存最后访问时间和低8位保存访问次数
- key 的访问次数不能只增不减,它需要根据时间间隔来做衰减,才能达到 LFU 的目的
- 每次在访问一个 key 时,会懒惰更新这个 key 的访问次数:先衰减访问次数,再更新访问次数
- 衰减访问次数,会根据时间间隔计算,间隔时间越久,衰减越厉害
- 因为 redisObject lru 字段宽度限制,这个访问次数是有上限的(8 bit 最大值 255),所以递增访问次数时,会根据当前访问次数和概率的方式做递增,访问次数越大,递增因子越大,递增概率越低
- Redis 实现的 LFU 算法也是近似LFU,是在性能和内存方面平衡的结果